让(并保持)你的网页在谷歌索引可能是一个挑战的新网站和网站 technical SEO or content quality issues. 本文旨在帮助您发现Google不为您的站点建立索引的潜在原因. Sometimes the issues can be a quick fix, however, 有时候,你必须深入挖掘谷歌没有索引你所有网页的真正原因.

How to Check Google’s Index of Your Site
为了首先确定您的页面(或整个网站)没有在谷歌索引, follow these steps:
- Use the “site:domain.com” query such as this example: site:storific.net. 这将向您显示Google在其搜索引擎中为域名索引的大多数(但可能不是全部)url. Google可能不会用此查询显示您站点上索引的所有页面,因为该查询可以在任意数量的Google数据中心完成, which all have somewhat different indexes. 您可能会看到或多或少的url索引您的网站与此查询在任何给定的一天. 提示:如果你的网站默认使用“www”子域名,在域名前添加“www”. 这将只显示为该子域索引的url.
- Use the “site:domain inurl:
” query such as this example: site:storific.net inurl:google-not-indexing-site. 这将显示谷歌是否有一个特定的页面索引. - Use the “site:domain filetype:
” query such as this example: site:storific.net filetype:xml. 这将显示Google是否为您的站点索引了具有特定文件类型的页面. - Check “Index Status” in Google Search Console. 这个方便的报告将让你看到(一眼)你的网站上有多少页被索引在谷歌的搜索引擎. 它还可以显示有多少url被阻止或已被删除. All three metrics are shown via a graph, over the course of a year, 随着时间的推移,它可以帮助你监控你的网站在谷歌的索引.
- Check “Sitemaps” in Google Search Console. This is another helpful report, 它将显示您的XML站点地图中有多少页已提交给Google, and how many are indexed. Similar to the Index Status report, 这个工具将向您展示一个月(而不是一年)的站点地图URL索引的时间轴。.
在谷歌搜索操作符上找到更多建议 here.
为什么谷歌不索引你的网站的常见原因
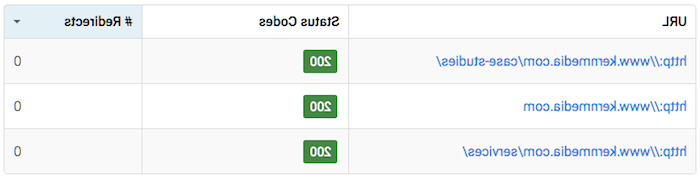
1. Response Codes Other than 200 (OK)
Perhaps it goes without saying, 但是如果您的页面没有产生200 (OK)的服务器响应代码, 然后,不要指望搜索引擎为它们索引(或者如果它们曾经被索引过,也不要让它们被索引)。. 有时url会意外地被重定向, 根据CMS问题产生404或500个错误, server issues, or user error. 做一个快速检查,以确保您的页面的URL是正确加载. 如果它加载了,你看到了,你可能就没事了. But, you can always run URLs through HTTPStatus.io to verify. Here’s what that looks like:
2. Blocked via Robots.txt
Your website’s /robots.txt file (located at http://www.domain.com/robots.(例如,txt)给谷歌它的抓取命令. 如果你网站上的某个特定页面在谷歌索引中丢失了, this is one of the first places to check. 谷歌可能会显示这样一条消息:“由于本网站的机器人,无法获得此结果的描述。.如果它之前索引了你网站上一个现在被机器人屏蔽的页面,那么它就会在URL下添加“txt”.txt. Here is what that looks like:
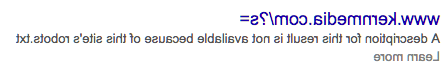
Check out my article on How to Write a Robots.txt File 有关优化这一重要元素的SEO工作的更多信息.
3. “Noindex” Meta Robots Tag
Another common reason why a page on your site may not be indexed in Google is that it may have a “noindex” meta robots tag of sorts in the
of the page. 当谷歌看到这个元机器人标签时,这是一个明确的指示,它不应该索引页面. Google will always respect this command, 根据编码方式的不同,它可以有多种形式:- noindex,follow
- noindex,nofollow
- noindex,follow,noodp
- noinde,nofollow,noodp
- noindex
下面是它的截图 in the
of a page: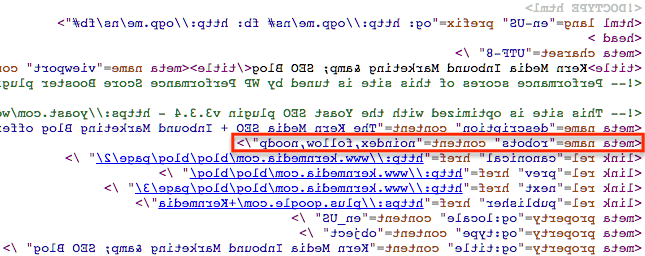
检查你的页面是否有“noindex”meta robots标签, view the source code and look for the code in the
. 如果你的网站是用javascript渲染的, then you may need to use the “Inspect Element” feature of Google Chrome to view the properly. More info here.4. “Noindex” X-Robots Tag
Similar to a meta robots tag, X-robots标记提供了通过页面级标记控制Google索引的能力. 但是,该标记用于特定页面或文档的标头响应. It is commonly used on non-HTML pages where there is no
, such as PDF files, DOC files, 以及其他网站管理员希望排除在谷歌索引之外的文件. 不太可能是不小心应用了“noindex”X-robots标签, however you can check using the SEO Site Tools extension for Chrome. 下面是它的截图.
5. Internal Duplicates
Internal content duplication is a risk to any SEO efforts. 内部重复的内容可能会也可能不会使你的网页远离谷歌的索引, 但是网页上大量的内部重复内容很可能会影响你的排名. 如果你有一个特定的页面与你网站上的另一个页面有大量相似的内容, 这可能就是你的页面没有被Google索引或者排名不好的原因.
要检查内部重复内容,我建议使用 Siteliner tool to crawl your website. 它将报告所有具有内部重复内容的页面, 突出显示重复的内容以方便参考, 并且还为您提供了一个简单的图形视图,显示您的网站上有多少内容被复制.

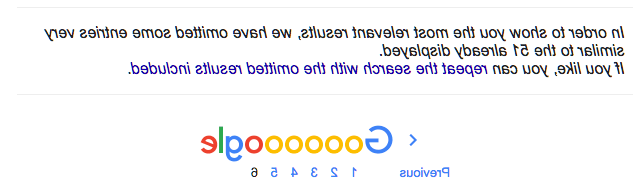
Google clearly states here 网站应该尽量减少类似的内容. 在你的网站上,内容非常相似的页面在某种程度上仍然可以排名, however, 内容完全相同的网页可能会被谷歌的即时搜索结果过滤掉. 在诸如以下的通知下,它们可以从搜索结果中省略.
6. External Duplicates
外部复制内容是你可能会想到的……与其他网站复制的内容. 对谷歌来说,大量重复内容是低质量的标志, and should be avoided at all costs. No matter whether your website is a lead generation marketing site, E-Commerce store, online publishing 平台,或业余爱好者的博客…同样的规则适用.
判断你的内容是否与其他网站重复的一种方法是将内容的一小段放在引号中,然后搜索谷歌, such as this example这表明家得宝的产品描述与许多其他网站重复. Note: Due to Home Depot’s brand authority, review content and other factors, 他们很可能仍然在谷歌的搜索结果中排名靠前. However, 不太权威的网站可能不会被完全索引,也不会因为重复的内容(如制造商提供的产品描述)而排名很好.
要检查外部重复内容,我建议使用 Copyscape 抓取你的站点地图或一组特定的url. 这个工具将提供一个非常有用的(和可导出的)报告,说明您的网站与外部网站的重复. 下面是它的截图(为了保护隐私,我客户端的URL和Title信息被模糊了).

7. Overall Lack of Value to Google’s Index
也有可能是一个特定的页面,或者你的网站作为一个整体,可以 suck so bad 它根本没有为谷歌的索引提供足够的价值. For example, 只有动态生成广告的联属网站对用户来说几乎没有价值. 谷歌已经改进了它的算法,以避免对这类网站进行排名(有时也会避免索引). 如果你关心你的网站质量, 仔细看看它为谷歌索引提供的独特价值, 哪些是其他网站没有提供的.
8. Your Website is Still New & Unproven
新网站不会神奇地很快被谷歌和其他搜索引擎编入索引. 谷歌需要链接和其他信号才能在搜索结果中对网站进行索引和排名(可见). 这就是为什么链接建设对新网站特别重要.
9. Page Load Time
If your site has pages that load slowly, and they’re not fixed, 随着时间的推移,谷歌可能会降低该页面的排名,该页面甚至可能从其搜索引擎索引中消失. Typically, the page will simply drop in the rankings, 但这几乎和没有被编入索引一样糟糕.
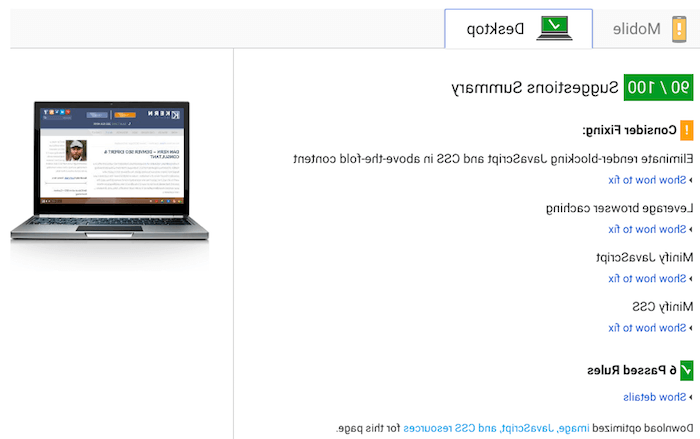
To check for page load time, you can use Google’s Page Speed Insights tool or the GTMetrix tool. 以下是谷歌工具提供的一个报告示例的截图.
10. Orphaned Pages
Google会抓取您的网站(和XML站点地图)来查找指向您的内容的链接, 更新它的索引,并影响你的网站在搜索结果中的排名(除其他因素外). 如果谷歌找不到链接到你的内容, either on your site or an external site, then it doesn’t exist to Google. It won’t be indexed. 没有内部链接的页面被称为“孤立页面”,,这可能是谷歌索引减少的一个原因. 以确定您的页面是否可被发现, 建议使用以下工具抓取您的站点 Screaming Frog. 然后搜索有问题的特定url. Here’s an example of what that looks like.
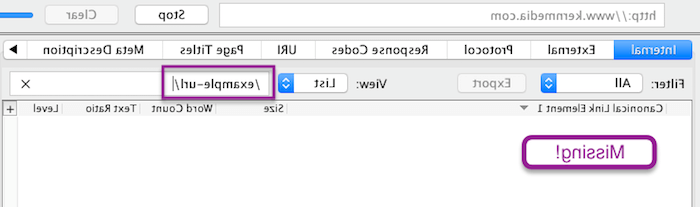
检查孤立页面的更健壮的方法是从尖叫青蛙爬行中导出url,并准备一个电子表格,将url与XML站点地图同步(假设它是准确的)。. 这将允许您立即识别所有url, which are included in your XML sitemap, but were not discovered during the crawl. 请记住,您的抓取设置可以决定抓取哪些url, 因此,建议您具有使用此工具的适当经验.
When in Doubt, Ask for Help
对有些人来说,这些东西太专业了,最好向专业人士咨询 SEO specialist像我一样🙂如果你卡住了,你需要确定你的时间有多宝贵. 花费深夜试图解决谷歌索引和排名将变得令人厌倦. 记住,索引并不等于最佳排名. Once Google has indexed your site, your content quality, 链接配置文件和其他网站和品牌信号将决定你的网站排名如何. 但是,索引是SEO之旅的第一步.